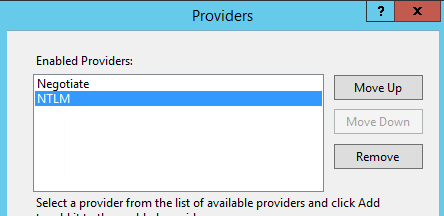
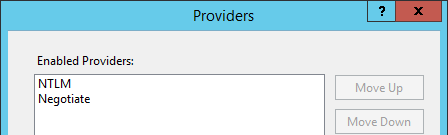
Granting user authentication from vRealize Automation (vRA) 7.2 to vRealize Orchestrator (vRO) is not as easy as it should be. I received an “Invalid Username or Password” error when logging into vRO, as shown below.  My vRA environment was configured to use my home lab Active Directory (AD) domain without any issue. Next I wanted to get my vRO appliance configured. I logged into the vRO Control Center to configure the authentication and other items. Since I am using the embedded vRO, the Authentication Provider is automatically set to vRealize Automation. The custom tenant was set and I was able to populate the AD groups from the dropdown without any issues. Since I could see my AD groups, I didn’t think vRO would have any issues with authenticating any user within my selected AD group. I was mistaken.
My vRA environment was configured to use my home lab Active Directory (AD) domain without any issue. Next I wanted to get my vRO appliance configured. I logged into the vRO Control Center to configure the authentication and other items. Since I am using the embedded vRO, the Authentication Provider is automatically set to vRealize Automation. The custom tenant was set and I was able to populate the AD groups from the dropdown without any issues. Since I could see my AD groups, I didn’t think vRO would have any issues with authenticating any user within my selected AD group. I was mistaken.
A quick search across blogs and forums did not provide much help. I went to the vExpert Slack channel and hit another roadblock. A couple members told me to follow a blog post from vCOTeam to correctly configure the domain login. I had already tried this without any success. The channel said that is how it works now and could not see much else from the logs I provided. With a bit more searching, I found a blog post on Spas Kaloferov’s blog that was my key to finding the solution to this problem, twice.
Solution 1
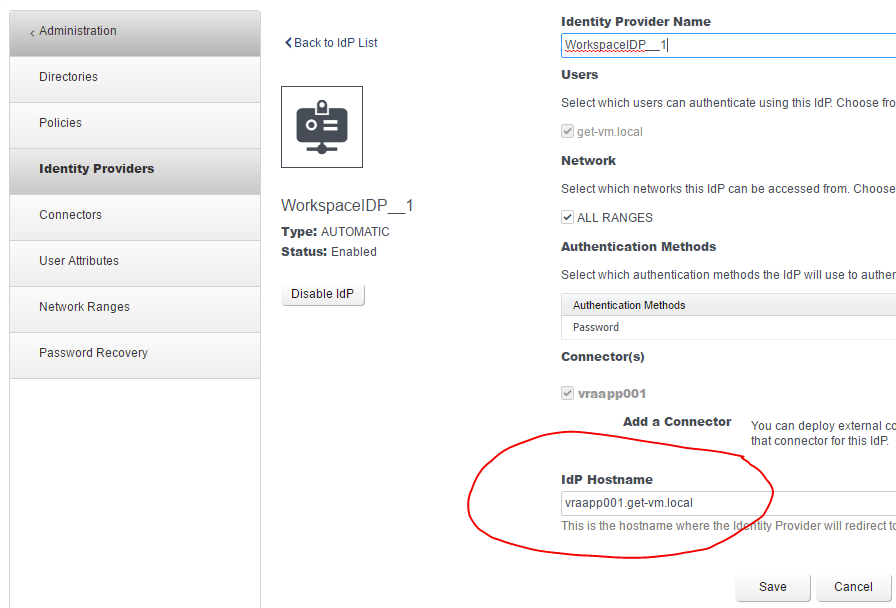
The solution that worked in my home lab was referenced under his misconfiguration of the Identity Provider in vRA. He mentions changing the IdP Hostname to the vRA Load Balancer address. Unfortunately, my vRA environment contains zero load balancers. I did notice that my IdP Hostname was not the vRA FQDN. It was set as the hostname with no domain suffix. After changing the IdP Hostname to the correct vRA FQDN, I was able to login with my AD user account.
Solution 2
While working with a client, I ran into this issue again. Immediately, I checked the IdP Hostname. This time, the IdP Hostname had the correct FQDN configured. Later, we accidentally discovered that the certificate that was generated by one of their team members had a misspelled FQDN for the vRA appliance and lacked another Subject Alternative Name (SAN). A new certificate was generated with all of the correct FQDNs and SANs required for our deployment. This proved to be the solution for their version of this issue.
In Conclusion
VMware needs to address this finicky configuration between vRA and vRO. There are too many variables that may cause this issue.
With the release of vRA/vRO 7.3, they changed the back-end authentication again and will probably eliminate this issue. However, they will create a new issue. They always do.


 I tried a few different things to resolve the issue like creating a new customization spec but everything I did always pointed back to vRA trying to initiate the next step after the VM was deployed from the template.
I tried a few different things to resolve the issue like creating a new customization spec but everything I did always pointed back to vRA trying to initiate the next step after the VM was deployed from the template.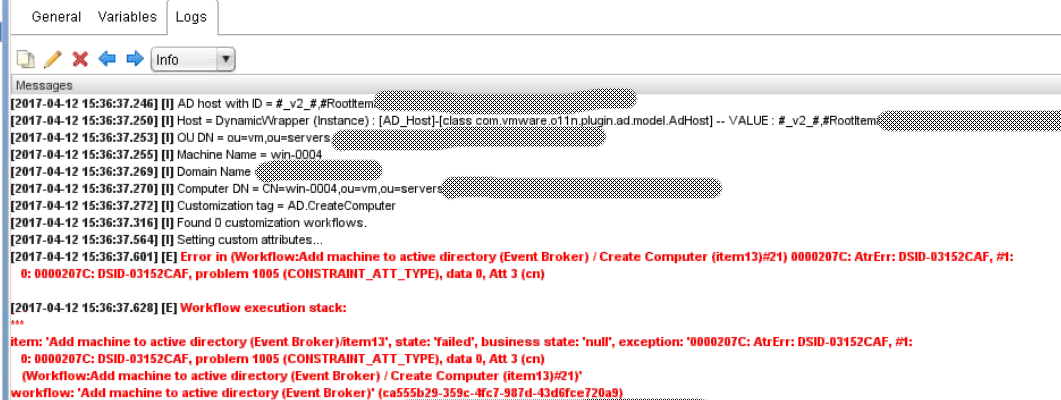

 f Python and Splunk, I was able to come up with some telling deficiencies/strengths on both sides of the ball. Dave attempted to provide the stats to his contacts on both sides two days before the big game. Both sides denied that stats unfortunately. All was not lost though. Our stats were gladly accepted by the TV commentators on the national broadcast. Four of my stats were mentioned on air. Another one of my stats that was not used but the opposite was said by Kirk Herbstreit on-air, proved to be true in favor of Alabama. Normally, my wife and I would have watched the game as we are huge football fans in general but really could have cared less considering the two teams. But since we knew there was a possibility that the stats could be used on-air it was one of the most interesting games to watch considering the statistical analysis that I had performed for the game. Who knows how the upcoming 2016 season will turn out and what stats I can come up with.
f Python and Splunk, I was able to come up with some telling deficiencies/strengths on both sides of the ball. Dave attempted to provide the stats to his contacts on both sides two days before the big game. Both sides denied that stats unfortunately. All was not lost though. Our stats were gladly accepted by the TV commentators on the national broadcast. Four of my stats were mentioned on air. Another one of my stats that was not used but the opposite was said by Kirk Herbstreit on-air, proved to be true in favor of Alabama. Normally, my wife and I would have watched the game as we are huge football fans in general but really could have cared less considering the two teams. But since we knew there was a possibility that the stats could be used on-air it was one of the most interesting games to watch considering the statistical analysis that I had performed for the game. Who knows how the upcoming 2016 season will turn out and what stats I can come up with.