Anyone with more than 3 hosts absolutely dreads removing data volumes from the VMware environment. It is a mind-blowing tedious and redundant process that VMware has yet to fully address. First you must unmount the volume(s) from all the hosts. This part, thankfully, is easy, it just requires you to select the proper datastore, right click, and select ‘Unmount’. A nice little wizard comes up and runs the appropriate checks to make sure the datastore can indeed be unmounted. Just hit next and select the hosts you wish to unmount from and VMware kicks off the unmount procedure for that datastore on the selected hosts.
Well if you thought you were done and ready to unpresent that datastore, you are mistaken. vSphere still sees that LUN and if you simply unpresent it from the hosts, they will really not like you one bit until you reboot them. You must go to each host’s configuration page for storage adapters, find the correct LUN, right click and detach. Here is one of VMware’s KB articles for those that need more information on the process.
Imagine the time it takes to go through 10 hosts, or how about 50 hosts without automation?
So…let’s fix that and automate the entire process via vCenter Orchestrator! Here is a quick run-down of what the workflow does. First thing you need to do when running the workflow is select the cluster the datastore is presented to.
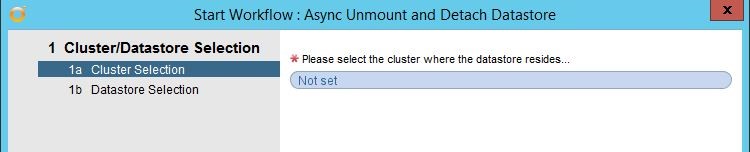
After selecting the proper cluster and hitting next, you are presented with a dialog to select your datastore or datastores you wish to unmounts and detach from the hosts in the selected cluster.
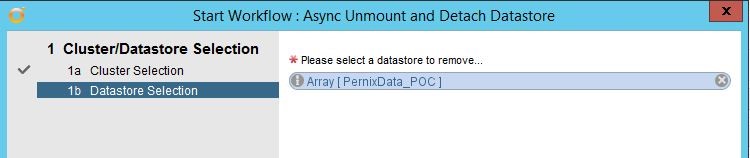
After selecting the datastores, just hit “submit” and away it goes. So what does it do? Here is what the schema looks like for the workflow.
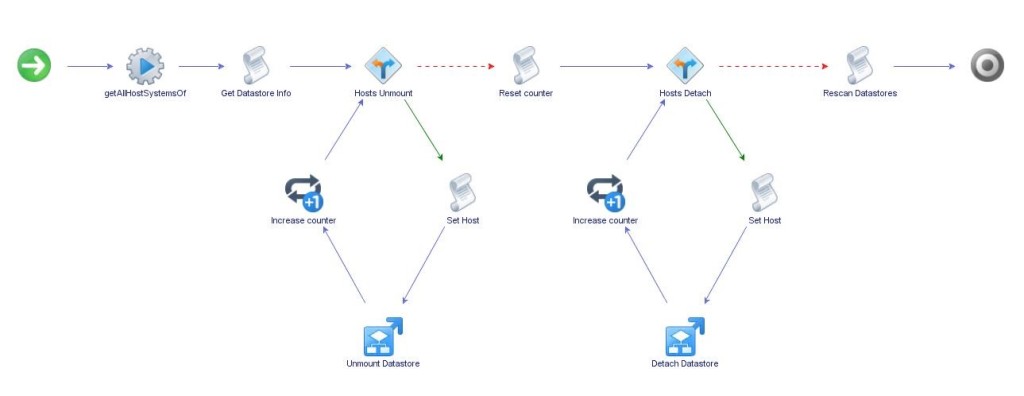
The workflow starts off by getting all the hosts of the cluster you select. It then grabs the needed information from the datastore(s) and stores it in a couple of arrays to be used later. Take a quick look at the actual scripting behind this.
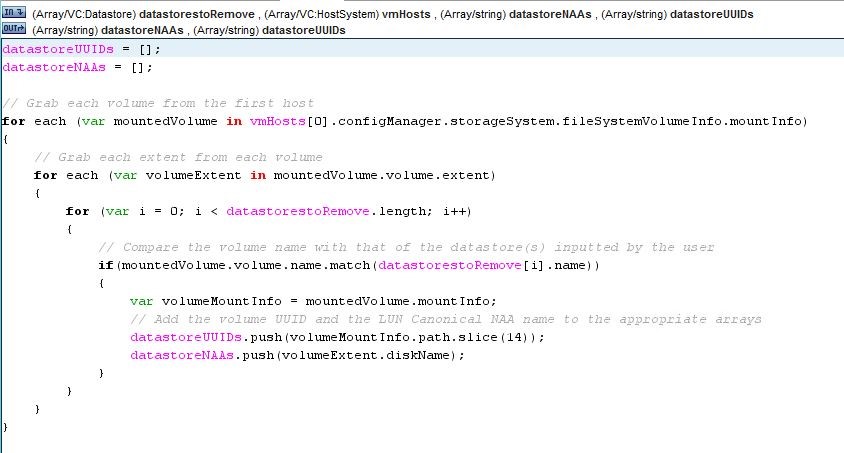
It grabs the UUIDs needed for the unmount procedure and the Canonical NAA name for the detach sequence. Who knows why VMware doesn’t allow these procedures to be done by just using just one of these variables, or at the very least fully documents the process, but this works…for now.
*Note: you might need to adjust the SLICE number in your environment to grab the correct UUID. 14 is what works in my environment.
So after the workflow has the necessary info, it can proceed to the unmount loop. We set the host to work with within the host array to the counter, then we kick off the unmount procedure that loops through each datastore in the datastore array that you selected and unmounts it on that host. Here is the scripting code for that workflow.

After it has looped through all the hosts, kicked off the unmounts and they finish, the workflow exits the unmount loop, resets the counter, and then drops into the detach loop. The detach loop has the same setup as the unmount loop, except it launches the detach workflow for each host instead of the unmount workflow. Take a look at its scripting code.

Once the detach loop is complete and all detach operations have finished, the workflow exits the detach loop, kicks off a rescan for datastores on the hosts in the cluster to clean up the LUN paths, and then exits.
That is pretty much it, all this is done asynchronously on the hosts to save even more time. Let me know what you think or if you have any questions. Have fun tailoring this workflow for your needs!
You can find this workflow package on either Github or Flowgrab.
Github: https://github.com/get-vm/vCO_Packages
Flowgrab: https://flowgrab.com/project/view.xhtml?id=0752edc8-a0fd-45fe-a675-4842732c4bad
April 21, 2015 Update: Updated workflow to 2.1.0 based on Jason’s feedback. There is now a sleep timer of 15 seconds and an initial counter reset before the unmount. The updated workflows were pushed to the links above.